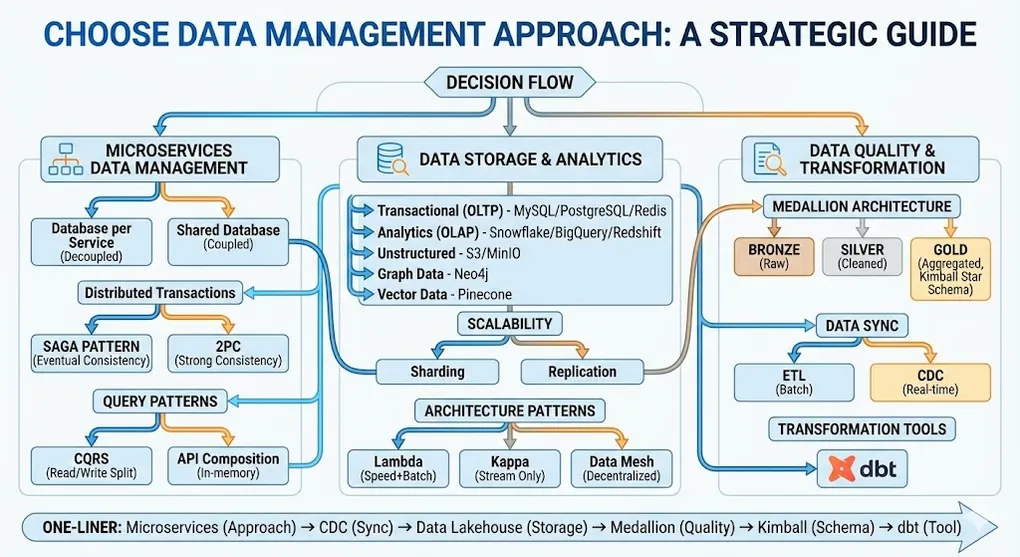
Choose Data Management Approach: A Strategic Guide
“Choose Data Management Approach” is not about picking a database software (Oracle vs MySQL). It’s about making architectural pattern decisions for how you store, access, maintain, and synchronize data across your system.
[!NOTE] This guide covers two distinct worlds:
Part Focus Concern Part 1: Operational Data (OLTP) Microservices, Transactions, Caching ”How do I keep my application running?” Part 2: Analytical Data (OLAP) ETL/CDC, Lambda/Kappa, Data Mesh ”How do I derive insights?” Part 3: The Bridge CQRS, CDC, Reverse ETL ”How does data flow from OLTP to OLAP?”
PART 1: Operational Data (OLTP)
How multiple services handle transactional data in real-time.
1. Microservices Architecture — The Most Common Context
In modern cloud-native development, this is the core decision point. You must decide how multiple services handle data.
The Options
Database per Service (Each Service Has Its Own Database)
- Definition: Each microservice owns its dedicated database. Other services cannot directly read/write — they communicate only via APIs.
- Advantages:
- Low coupling between services (Decoupling)
- Teams can choose the best-fit database technology (Polyglot Persistence)
- Example: Order Service uses SQL, Logging Service uses NoSQL
- Challenges:
- Distributed transactions are extremely difficult
- Typically requires Saga Pattern for eventual consistency
- Best For: Most standard microservices architectures
Shared Database
- Definition: Multiple microservices share one large database.
- Advantages:
- Easy to maintain ACID transaction consistency
- Fast initial development
- Challenges:
- High coupling between services
- Schema changes affect all services
- Difficult to scale
- Generally considered an Anti-pattern, but common during legacy migration
2. Distributed Transaction Management
In monolithic architecture, we rely on database ACID (Atomicity, Consistency, Isolation, Durability). In distributed systems, we must choose how to handle cross-service transactions.
2PC (Two-Phase Commit)
- Mechanism: Strong consistency. All participating databases must lock and commit simultaneously.
- Trade-off: Extremely poor performance. Resource locking can cause system deadlocks (Blocking).
- Usage: Rarely used in modern cloud architectures.
Saga Pattern
- Mechanism: Break one large transaction into a series of small transactions. If a step fails, execute Compensating Transactions to undo previous operations.
Two Implementation Styles
| Style | Description |
|---|---|
| Orchestration | A central Orchestrator tells each service what to do |
| Choreography | Services trigger each other via Events — no central coordinator |
[!TIP] When to use which?
- Orchestration: Complex workflows with many steps, need visibility/debugging, central control preferred. Avoids “distributed spaghetti.”
- Choreography: Simple flows, highly decoupled services, teams deploying independently. Beware: hard to debug when things go wrong.
Saga Compensation Design: E-Commerce Example
Consider an order flow: Create Order → Reserve Inventory → Process Payment → Ship
┌──────────────────────────────────────────────────────────────┐
│ SAGA: Order Processing │
├──────────────────────────────────────────────────────────────┤
│ Step 1: Create Order │ Compensate: Cancel Order │
│ Step 2: Reserve Inventory │ Compensate: Release Stock │
│ Step 3: Process Payment │ Compensate: Refund Payment │
│ Step 4: Ship Order │ Compensate: Cancel Shipment │
└──────────────────────────────────────────────────────────────┘
If Step 3 (Payment) fails:
→ Execute Compensate Step 2 (Release Stock)
→ Execute Compensate Step 1 (Cancel Order)
→ Notify user of failureKey Design Principles
- Idempotency: Each step must be safe to retry (use unique transaction IDs)
- Ordering: Compensations execute in reverse order
- Timeout Handling: Set deadlines; if no response, assume failure
- Dead Letter Queue: Failed compensations go to DLQ for manual review
Saga Compensation Flow Diagram
┌─────────────────────────────────────────────────────────────────────────────┐
│ SAGA: Order Processing - Compensation Flow │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ HAPPY PATH (All Steps Succeed) │
│ ───────────────────────────────── │
│ │
│ [Create Order] ──▶ [Reserve Stock] ──▶ [Charge Payment] ──▶ [Ship] ──▶ ✅ │
│ Step 1 Step 2 Step 3 Step 4 │
│ │
│ ═══════════════════════════════════════════════════════════════════════ │
│ │
│ FAILURE PATH (Step 3 Fails - Payment Declined) │
│ ───────────────────────────────────────────── │
│ │
│ [Create Order] ──▶ [Reserve Stock] ──▶ [Charge Payment] ──▶ ❌ FAIL │
│ Step 1 Step 2 Step 3 │
│ │ │
│ ▼ │
│ Trigger Compensation │
│ │ │
│ ▼ │
│ [Cancel Order] ◀── [Release Stock] ◀──────────┘ │
│ Compensate 1 Compensate 2 │
│ │
│ Result: System returns to consistent state (no orphan orders) │
│ │
└─────────────────────────────────────────────────────────────────────────────┘3. Query Patterns: Solving Cross-Database Queries
When data is scattered across different microservice databases, generating a report that combines “User Data + Order Data + Payment Status” becomes challenging.
API Composition
- Mechanism: An upper-layer API Gateway calls multiple services and assembles data in memory.
- Drawbacks: Poor performance, high memory consumption, cannot do complex sorting/pagination.
CQRS (Command Query Responsibility Segregation)
- Mechanism: Separate the “Write” (Command) and “Read” (Query) models.
- Implementation:
- Write to relational database (e.g., MySQL)
- Sync via events to a read-optimized database (e.g., Elasticsearch, Redis)
- Advantages: Extremely fast reads, flexible querying
- Drawbacks: High system complexity, data delay (milliseconds before writes are readable)
Handling CQRS Data Delay
The #1 challenge with CQRS: User writes data, but immediately reads stale data.
Strategies to mitigate:
| Strategy | Description | Trade-off |
|---|---|---|
| Read-Your-Writes | After write, query the write-DB directly for that user’s session | Adds complexity, partial consistency |
| Optimistic UI | Frontend immediately shows the expected result before sync completes | May show incorrect data if write fails |
| Polling / WebSocket | Client polls or subscribes to updates until read-DB catches up | Adds network overhead |
| Version Tokens | Attach version number to writes; reads wait until version matches | Guarantees consistency, adds latency |
Best Practice: For user-facing writes, use Optimistic UI + Read-Your-Writes fallback. For background analytics, eventual consistency is acceptable.
PART 2: Analytical Data (OLAP)
How data flows to warehouses, lakes, and analytics platforms.
4. Data Synchronization: Moving Data Between Systems
Data rarely stays static — it flows from System A to System B (e.g., from “Transaction DB” to “Analytics Platform”).
ETL (Extract, Transform, Load)
- Mechanism: Traditional batch processing. Pull data nightly for transformation.
- Drawback: Data has time lag (T+1), cannot support real-time decisions.
CDC (Change Data Capture)
- Mechanism: Listen to database logs (e.g., MySQL Binlog). When data changes, immediately send events (via Kafka, etc.).
- Application: This is the mainstream approach for real-time data sync in modern architectures.
5. Scalability Strategies
When choosing a data management approach, you must anticipate future scaling paths.
Sharding (Horizontal Partitioning)
- Mechanism: Split one large table into smaller fragments distributed across different machines.
- Critical Decision: Sharding Key selection is crucial. Wrong key leads to data skew (one machine overloaded).
Replication
| Type | Description | Use Case |
|---|---|---|
| Master-Slave | Write to master, read from slaves | Read-heavy workloads |
| Multi-Master | Multiple machines can read/write | High complexity, requires conflict resolution |
6. Caching Strategy
Data management isn’t just about “storing” — it’s also about “caching.”
Patterns
| Pattern | Description |
|---|---|
| Cache-Aside | App checks cache first; if miss, query DB, then write to cache |
| Write-Through | Data written to cache and DB simultaneously |
| Write-Back | Only update cache, async write to DB |
Decision Point
- What TTL (Time-to-Live) can your data tolerate?
- What happens if cache and database become inconsistent?
7. Consistency Models
Strong Consistency
- Example: Bank transfers — reads always return the latest data
- Trade-off: May sacrifice performance or availability (ACID principles)
Eventual Consistency
- Example: Social media like counts — allows brief inconsistency
- Trade-off: Gains extreme performance and availability (BASE principles)
Causal Consistency (The Practical Middle Ground)
[!IMPORTANT] Real-world systems often target Causal/Read-Your-Writes consistency—not full strong consistency.
- Example: “I just posted a comment, I need to see it immediately. But others can see it 5 seconds later.”
- Implementation: Track version or session; your own writes are strongly consistent, others are eventually consistent.
- Also called: Read-Your-Writes, Session Consistency
| Model | Guarantee | Cost | Use Case |
|---|---|---|---|
| Strong | Latest data always | High (performance) | Banking, inventory |
| Causal/RYW | Your writes visible immediately | Medium | Social apps, comments |
| Eventual | Data converges eventually | Low | Likes, view counts |
8. Architecture Patterns
Lambda Architecture (Classic Big Data)
- Feature: Maintains two parallel paths
- Speed Layer: Real-time data processing (Kafka + Flink) — fast but approximate
- Batch Layer: Historical full data processing (Hadoop/Spark) — accurate, runs nightly to correct data
- Best For: Financial risk control, real-time ad bidding
Kappa Architecture (Simplified Streaming)
- Feature: Single path. All data treated as “Stream.”
- Core: Both historical and new data go through the same Stream Processing engine via Kafka.
- Advantage: Write code once, lower maintenance cost.
- Best For: Most modern real-time analytics systems.
Data Mesh (Decentralized Architecture)
- Feature: No single giant Data Lake. Treat data as “Products.” Each Domain Team (Orders Team, Members Team) manages and provides APIs for their own data.
- Best For: Large organizations where central IT becomes a bottleneck.
The Four Principles of Data Mesh:
┌─────────────────────────────────────────────────────────────────┐
│ Data Mesh: Four Principles │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 1. Domain │ │ 2. Data as a │ │
│ │ Ownership │ │ Product │ │
│ │ │ │ │ │
│ │ Teams OWN their │ │ SLAs, docs, quality│ │
│ │ domain's data │ │ like a product │ │
│ └────────────────────┘ └────────────────────┘ │
│ │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 3. Self-Serve │ │ 4. Federated │ │
│ │ Platform │ │ Governance │ │
│ │ │ │ │ │
│ │ Infra teams can │ │ Global standards, │ │
│ │ use independently │ │ local autonomy │ │
│ └────────────────────┘ └────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘⚠️ Data Mesh is organizational, not just technical. Requires mature teams with data skills in each domain.
PART 3: The Bridge (OLTP → OLAP)
How operational data flows to analytical systems.
| Pattern | Direction | Mechanism | Latency |
|---|---|---|---|
| CDC | OLTP → OLAP | Listen to DB logs | Near real-time |
| CQRS | OLTP → Read Store | Event sync | Milliseconds |
| Reverse ETL | OLAP → OLTP | Push insights back | Scheduled |
9. Decision Matrix
| Your Requirement | Recommended Approach | Key Technologies | 💰 Cost |
|---|---|---|---|
| High concurrent reads | Read-Write Separation + Cache | CQRS, Redis, Elasticsearch | Medium (ops) |
| Complex writes across services | Eventual Consistency | Saga Pattern, Kafka, RabbitMQ | Medium (dev) |
| Reports & complex search | Sync to search engine | CDC, Elasticsearch, Data Lake | Low |
| Highly connected data (social) | Graph Database | Neo4j, Amazon Neptune | Medium |
| AI applications (RAG, semantic search) | Vector Database | Pinecone, Milvus, Weaviate, Qdrant | High (growing) |
| Decentralized data ownership | Data Mesh | DataHub, Unity Catalog | Very High (organizational) |
[!WARNING] Cost Considerations:
- CQRS/Event Sourcing: High development complexity (maintaining 2 models)
- Data Mesh: Organizational cost — requires mature teams, not just tooling
- Shared Database: Low cost initially, but technical debt accumulates
- Vector Databases: Rapidly growing in RAG/LLM applications (2024-2026 trend)
10. Technology Stack by Scenario
| Scenario | Recommended Stack |
|---|---|
| Transactional (OLTP) — App backend | Primary: PostgreSQL / MySQL, Cache: Redis |
| Analytics (OLAP) — BI, Reports | Warehouse: Snowflake / BigQuery / Redshift, Transform: dbt |
| Unstructured Data — Images, Logs | Storage: S3 / MinIO, Search: Elasticsearch / MongoDB |
| High Concurrency — Flash sales, Gaming | In-Memory: Redis Cluster / DynamoDB |
| Complex Relationships — Social, Recommendations | Graph: Neo4j / Amazon Neptune |
| AI/RAG Applications — Semantic search, LLM context | Vector: Pinecone, Milvus, Weaviate, Qdrant, Chroma |
11. Non-Functional Requirements
Don’t forget these three make-or-break details:
Scalability
Can the database scale horizontally (Sharding) if traffic increases 10x? Or only vertical scaling (upgrade hardware)?
Reliability
- RPO (Recovery Point Objective): How much data loss is acceptable when system fails? (0 seconds? 1 hour?)
- RTO (Recovery Time Objective): How long to recover the system?
Governance & Security
- Who has permission to view PII (Personal Identifiable Information)?
- Is there Data Masking?
Framework: How to Choose?
When designing, answer these questions:
- Volume: TB-scale or PB-scale?
- Read/Write Ratio: Read-heavy (content sites) or write-heavy (sensor logs)?
- Consistency Requirements: Can you tolerate reading 2-second-old data?
- Service Boundaries: Do teams need independent deployment without interference?
Quick Decision Guide by Organization Type
| Organization | Recommendation | Rationale |
|---|---|---|
| Early-stage Startup | Start with Shared Database + Data Warehouse (BigQuery/Snowflake) | Simplest setup, SQL-ready, lowest maintenance |
| Growth-stage with Tech Debt | Migrate to Database per Service + CDC sync | Decouple gradually, don’t break existing flows |
| Enterprise with Unstructured Data | Data Lake + Data Warehouse (Lambda) or Data Lakehouse | Handle both structured & unstructured |
| Large Enterprise with Data Silos | Consider Data Mesh philosophy | Organizational change, not just tooling |
Identify Your Pain Point
Before choosing architecture, ask:
Is your problem technical or organizational?
| Pain Point | Root Cause | Solution Direction |
|---|---|---|
| ”Queries are too slow” | Technical: indexing, caching, read replicas | CQRS + Redis/Elasticsearch |
| ”Getting data requires waiting for another team’s approval” | Organizational: centralized data ownership | Data Mesh mindset |
| ”We can’t iterate fast enough” | Technical: tight coupling | Database per Service |
| ”We keep losing data during deploys” | Technical: no transaction guarantees | Saga Pattern with compensation |
The One-Liner Summary
Decide on Microservices (Data Management Approach) → Sync data via CDC to Data Lakehouse (Storage) → Adopt Medallion Architecture (Data Quality Layers) → Use Kimball (Star Schema) for the Gold Layer (Reporting) → Implement with dbt (Transformation Tool)