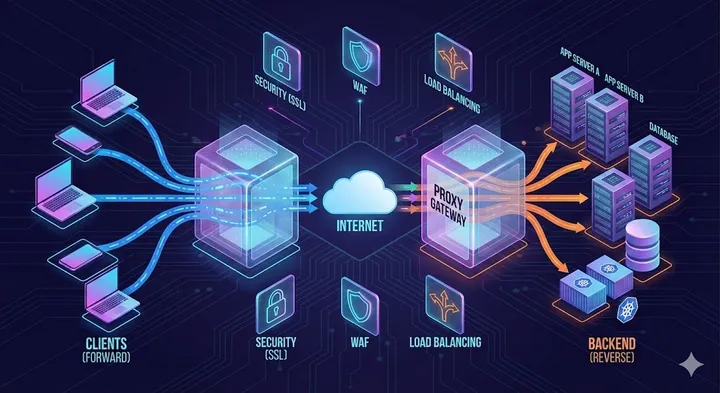
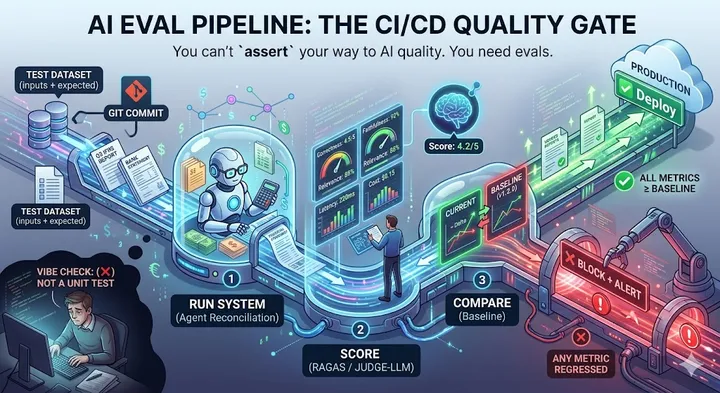
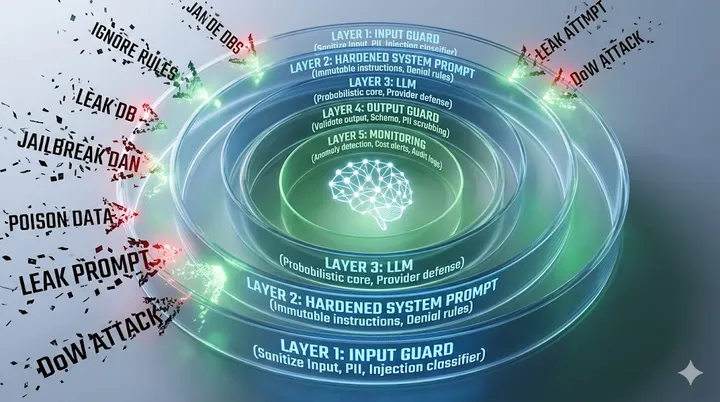
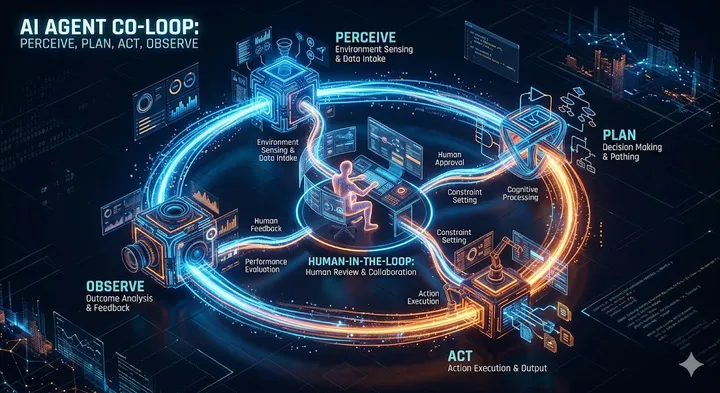
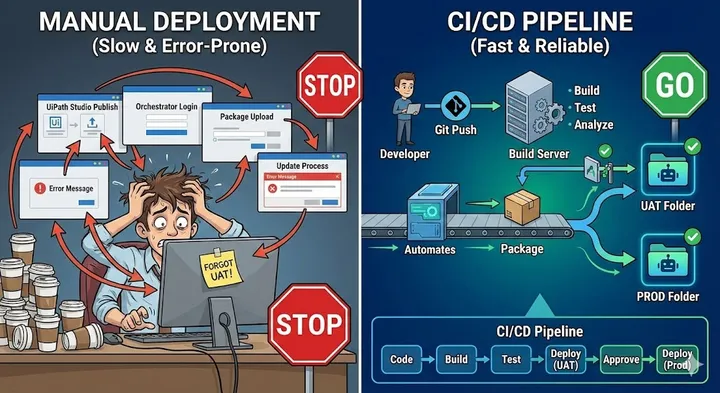
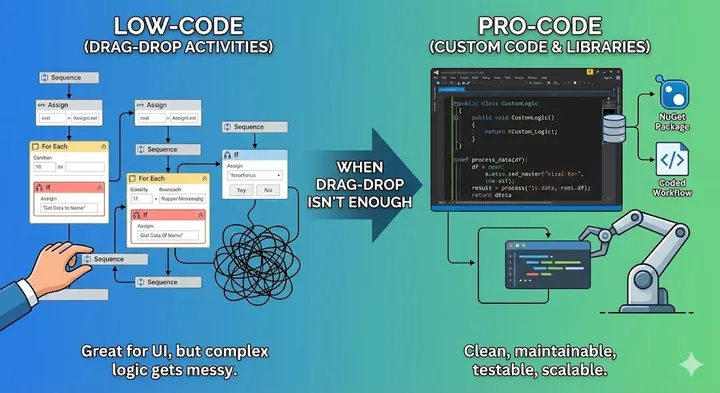
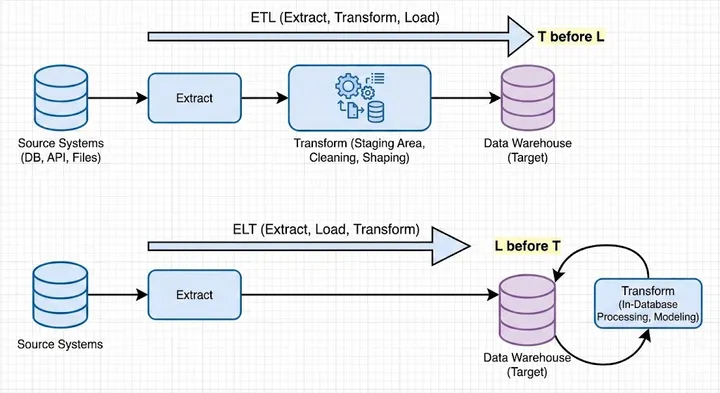
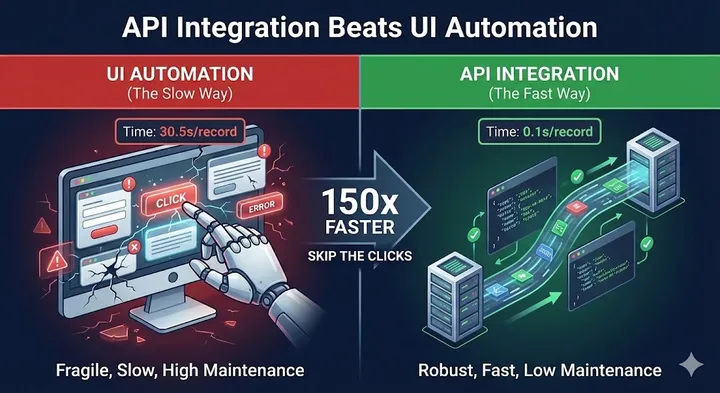
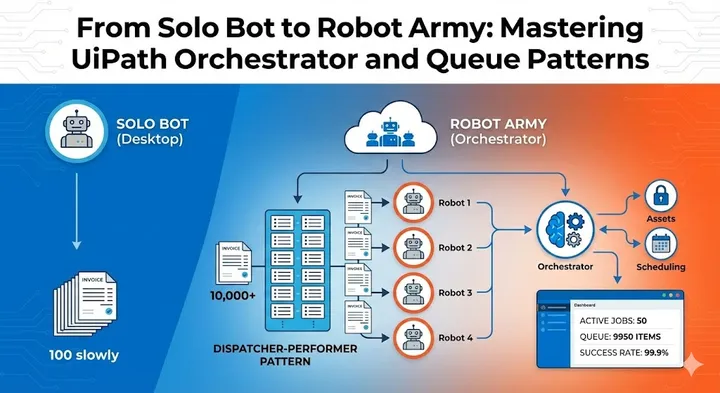
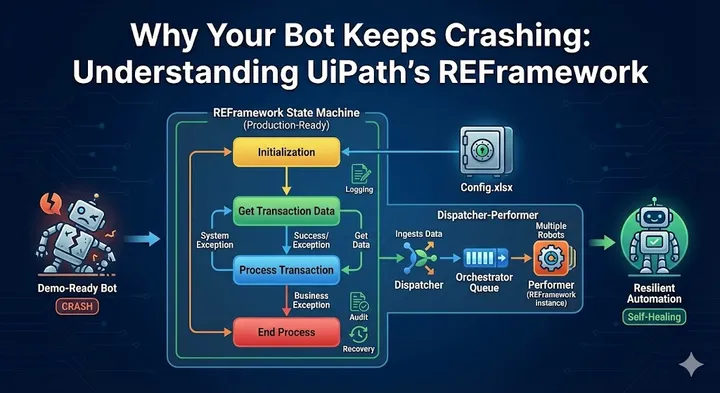
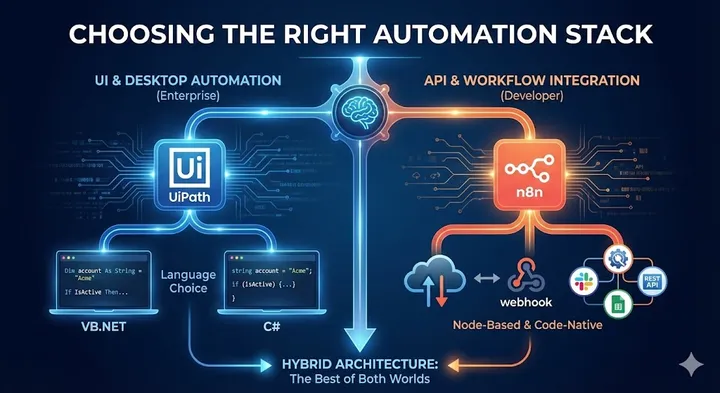
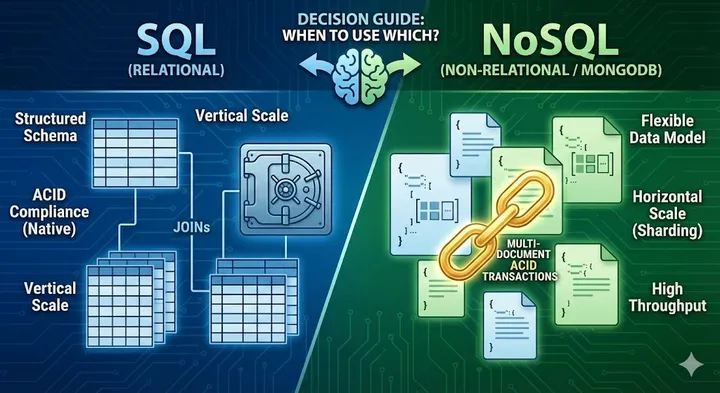
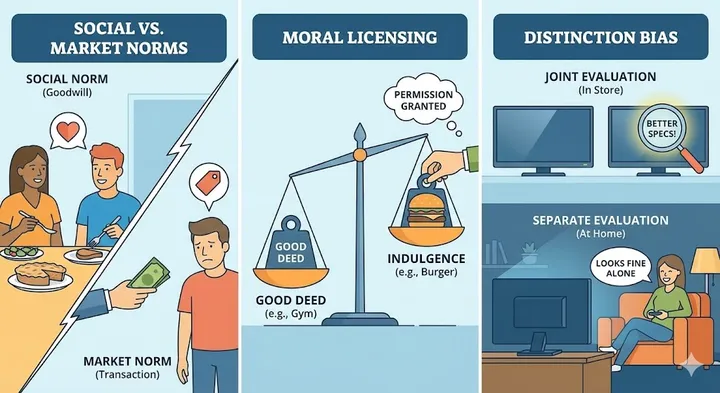
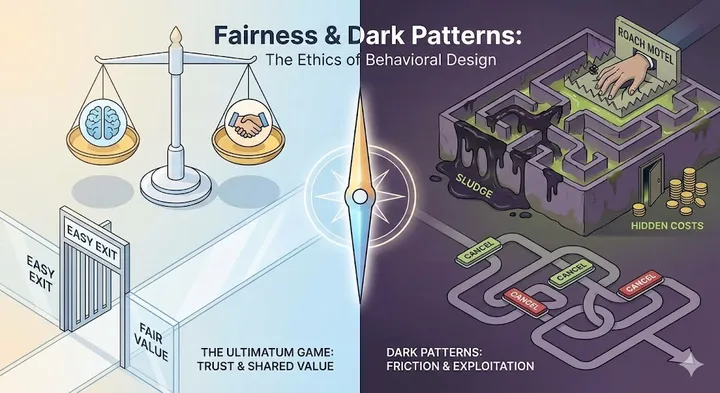
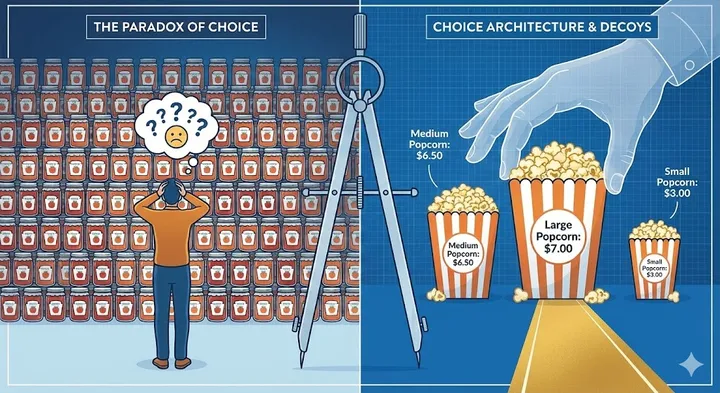
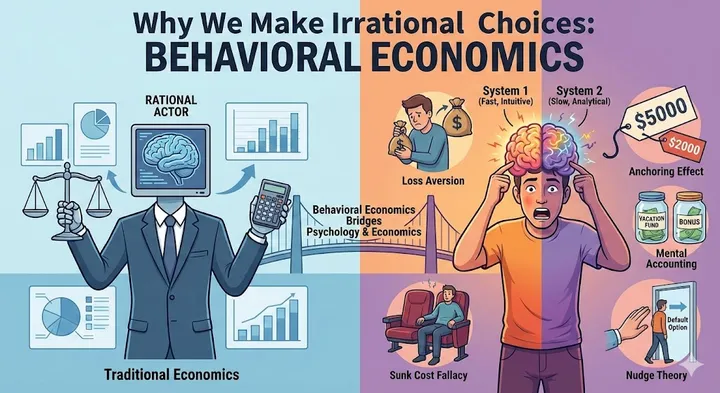
The Art of Asking: Mental Models That Transform How You Talk to AI
From the X-Y Problem to Shannon Entropy — 45 mental models across engineering, psychology, philosophy, and information theory that teach you to define the right problem, dodge cognitive traps, and make AI actually work for you.