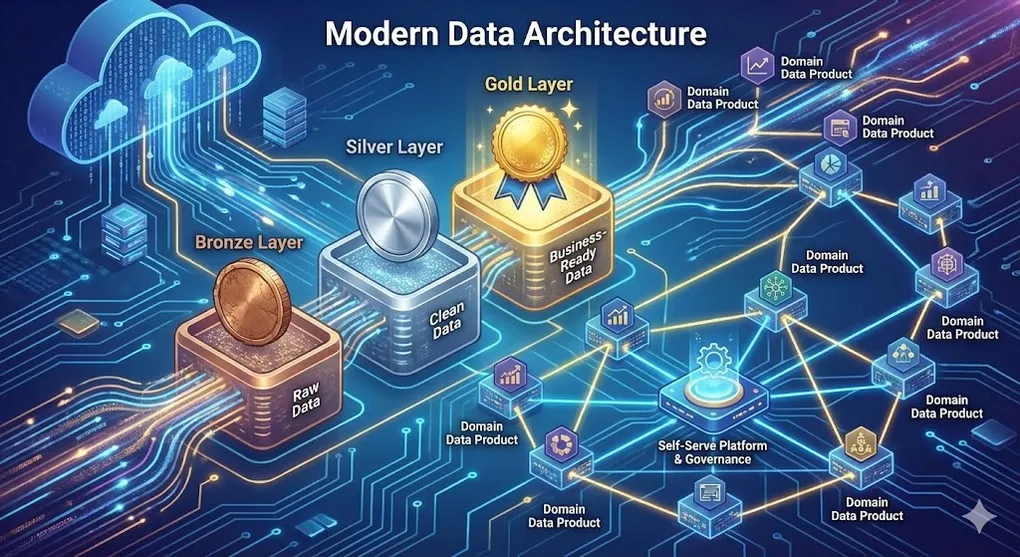
Modern Data Architecture: Medallion, Data Mesh & Beyond
The Modern Challenge
Traditional centralized data teams don’t scale. As organizations grow, they face:
- ⏱️ Bottlenecks: Central team can’t serve all domains
- 🔄 Slow Iterations: Weeks/months for new data products
- 📉 Quality Issues: Teams far from data don’t understand it
- 🏢 Silos: Departments build shadow data systems
Modern architectures address these through layered organization (Medallion) and decentralized ownership (Data Mesh).
The Underlying Principle: Separation of Concerns (SoC)
Both Medallion and Data Mesh embody the software engineering principle of Separation of Concerns:
| Architecture | SoC Application |
|---|---|
| Medallion | Each layer has ONE job: Bronze (ingest), Silver (clean), Gold (serve) |
| Data Mesh | Each domain owns its data end-to-end, platform provides shared infrastructure |
| Combined | Clear boundaries prevent “spaghetti pipelines” where everything depends on everything |
Why SoC Matters in Data: Without clear separation, a schema change in Bronze breaks Gold reports. With SoC, each layer acts as a contract boundary—changes are isolated and testable.
1. Medallion Architecture
Definition
Medallion Architecture is a data design pattern that organizes data into progressive layers of quality and refinement: Bronze → Silver → Gold.
The Three Layers
┌─────────────────────────────────────────────────────────────────┐
│ Medallion Architecture │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Source │───▶│ Bronze │───▶│ Silver │───▶│ Gold │ │
│ │ Systems │ │ (Raw) │ │ (Clean) │ │ (Mart) │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ Raw Data Processed Business- │
│ Exact Copy Validated Ready Data │
│ │
└─────────────────────────────────────────────────────────────────┘🥉 Bronze Layer (Raw / Landing)
| Aspect | Description |
|---|---|
| Purpose | Preserve raw data exactly as received |
| Content | JSON, CSV, Parquet dumps, API responses |
| Transformations | Minimal: add ingestion timestamp, source metadata |
| Schema | Schema-on-read or inferred |
| Retention | Long-term (years) for replay/audit |
-- Bronze table example
CREATE TABLE bronze.raw_orders (
_ingestion_timestamp TIMESTAMP,
_source_file STRING,
_raw_data STRING -- Original JSON/payload
);
-- Or structured but raw
CREATE TABLE bronze.orders (
order_id STRING,
customer_id STRING,
order_date STRING, -- Still string, not parsed
amount STRING, -- Still string
_ingestion_ts TIMESTAMP,
_source STRING
);Why keep raw data?
- 🔄 Replayability: Re-process if logic changes
- 🔍 Debugging: Trace issues to source
- ⚖️ Compliance: Audit trail for regulators
- 📊 Flexibility: Build new Silver tables without re-ingesting
🥈 Silver Layer (Clean / Staging)
| Aspect | Description |
|---|---|
| Purpose | Single source of truth, cleaned and validated |
| Content | Typed, deduplicated, standardized tables |
| Transformations | Parsing, casting, deduplication, validation |
| Schema | Enforced, documented |
| Consumers | Analysts, data scientists, Gold layer |
-- Silver table: cleaned, typed, deduplicated
CREATE TABLE silver.orders (
order_id INT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
amount DECIMAL(12,2),
currency VARCHAR(3),
status VARCHAR(20),
_loaded_at TIMESTAMP,
_updated_at TIMESTAMP
);
-- Transformation from Bronze to Silver
INSERT INTO silver.orders
SELECT
CAST(order_id AS INT),
CAST(customer_id AS INT),
PARSE_DATE(order_date),
CAST(amount AS DECIMAL(12,2)),
UPPER(TRIM(currency)),
status,
CURRENT_TIMESTAMP,
CURRENT_TIMESTAMP
FROM bronze.orders
WHERE order_id IS NOT NULL
QUALIFY ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY _ingestion_ts DESC) = 1;Silver Layer Responsibilities:
- ✅ Data type casting
- ✅ Null handling
- ✅ Deduplication
- ✅ Standardization (formats, codes)
- ✅ Data quality checks
- ✅ Soft deletes / SCD handling
🥇 Gold Layer (Serve / Mart)
| Aspect | Description |
|---|---|
| Purpose | Business-ready, optimized for consumption |
| Content | Aggregated KPIs, Star Schemas, feature tables |
| Transformations | Business logic, aggregations, dimensional modeling |
| Schema | Star/Snowflake Schema |
| Consumers | BI tools, executives, ML models |
-- Gold table: aggregated, business-ready
CREATE TABLE gold.daily_sales_summary (
date_key INT REFERENCES gold.dim_date(date_key),
store_key INT REFERENCES gold.dim_store(store_key),
product_category VARCHAR(50),
total_orders INT,
total_revenue DECIMAL(15,2),
avg_order_value DECIMAL(10,2),
unique_customers INT,
_computed_at TIMESTAMP
);
-- Gold transformation
INSERT INTO gold.daily_sales_summary
SELECT
d.date_key,
s.store_key,
p.category,
COUNT(*) as total_orders,
SUM(o.amount) as total_revenue,
AVG(o.amount) as avg_order_value,
COUNT(DISTINCT o.customer_id) as unique_customers,
CURRENT_TIMESTAMP
FROM silver.orders o
JOIN gold.dim_date d ON o.order_date = d.full_date
JOIN gold.dim_store s ON o.store_id = s.store_id
JOIN gold.dim_product p ON o.product_id = p.product_id
GROUP BY d.date_key, s.store_key, p.category;Gold Layer Patterns:
- ⭐ Star Schema: Fact + Dimension tables (Kimball)
- 📊 Wide Tables: Pre-joined, denormalized for specific use cases
- 🤖 Feature Store: ML-ready feature tables
- 📈 Aggregates: Pre-computed KPIs and metrics
Semantic Layer Trend (2024-2025): To prevent “What is Revenue?” debates (different definitions across departments), modern stacks add a Semantic Layer (Metric Store) on top of Gold:
- Tools: dbt Semantic Layer, Cube, Looker, Metricflow
- Purpose: Single source of truth for metric definitions, consumed by all BI tools
- Pattern:
Gold Tables → Semantic Layer → BI Dashboards
Layer Comparison
| Aspect | Bronze | Silver | Gold |
|---|---|---|---|
| Data Quality | As-is | Validated | Business-ready |
| Schema | Loose | Enforced | Optimized |
| Transformations | None | Technical | Business logic |
| Consumers | Engineers | Analysts, DS | BI, Executives |
| Query Pattern | Rare | Exploratory | High-frequency |
| Update Frequency | Real-time / micro-batch | Near real-time | Scheduled batch |
dbt Implementation
models/
├── staging/ # Bronze → Silver
│ ├── stg_orders.sql
│ └── stg_customers.sql
├── intermediate/ # Silver transformations
│ └── int_orders_enriched.sql
└── marts/ # Gold layer
├── dim_customer.sql
├── dim_product.sql
└── fct_sales.sql-- models/staging/stg_orders.sql
{{ config(materialized='view') }}
SELECT
order_id::int as order_id,
customer_id::int as customer_id,
order_date::date as order_date,
amount::decimal(12,2) as amount,
UPPER(TRIM(status)) as status
FROM {{ source('raw', 'orders') }}
WHERE order_id IS NOT NULL
-- models/marts/fct_sales.sql
{{ config(materialized='table') }}
SELECT
{{ dbt_utils.generate_surrogate_key(['o.order_id']) }} as sale_key,
d.date_key,
c.customer_key,
p.product_key,
o.quantity,
o.amount as revenue
FROM {{ ref('stg_orders') }} o
JOIN {{ ref('dim_date') }} d ON o.order_date = d.full_date
JOIN {{ ref('dim_customer') }} c ON o.customer_id = c.customer_id
JOIN {{ ref('dim_product') }} p ON o.product_id = p.product_idMulti-hop Architecture: How Many Layers?
The standard Medallion pattern uses 3 layers, but real-world complexity may require more or fewer.
Layer Spectrum
Simplest Standard Medallion Complex Enterprise
│ │ │
▼ ▼ ▼
┌─────────┐ ┌─────────────────┐ ┌─────────────────────┐
│ Raw→Gold│ │Bronze→Silver→Gold│ │Bronze→Silver→Silver+│
│ (2 hop) │ │ (3 hop) │ │ →Gold→Gold+ │
└─────────┘ └─────────────────┘ │ (4-5 hop) │
└─────────────────────┘Layer Count Decision Matrix
| Scenario | Recommended Hops | Reason |
|---|---|---|
| Simple BI reporting | 2 (Raw → Mart) | Low complexity, fast delivery |
| Standard analytics platform | 3 (Bronze/Silver/Gold) | Balance flexibility & maintenance |
| Multi-source integration | 3-4 | Split Silver: cleaned + integrated |
| Multi-consumer requirements | 3-4 | Split Gold: core + dept_specific |
| Strict regulatory environment | 4+ | Additional audit/compliance layer |
Signals to Add More Layers
| Signal | Action |
|---|---|
| Silver models too complex | Split into silver_stg + silver_conform |
| Multiple Gold tables repeat same JOINs | Add Intermediate layer |
| Different departments need different granularity | Add department-specific Gold |
| Need complete audit trail | Add archive layer |
dbt Common Layer Structure
models/
├── staging/ # Bronze → Silver (1st hop)
├── intermediate/ # Silver → Silver (2nd hop) ← Optional
├── marts/ # Silver → Gold (3rd hop)
│ ├── core/ # Shared Gold
│ └── finance/ # Department-specific Gold (4th hop)
└── reports/ # Pre-aggregated reports (5th hop) ← OptionalRule of Thumb: Start with 3 layers. Add more only when you see clear signals of complexity. Each additional layer increases maintenance overhead.
2. Data Mesh
Definition
Data Mesh is a sociotechnical approach that decentralizes data ownership to domain teams while providing a self-serve infrastructure.
Created by Zhamak Dehghani at Thoughtworks (2019)
The Four Principles
┌─────────────────────────────────────────────────────────────────┐
│ Data Mesh Principles │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 1. Domain │ │ 2. Data as a │ │
│ │ Ownership │ │ Product │ │
│ │ │ │ │ │
│ │ Teams own their │ │ Treat data like │ │
│ │ domain's data │ │ a product with │ │
│ │ │ │ SLAs & docs │ │
│ └────────────────────┘ └────────────────────┘ │
│ │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ 3. Self-Serve │ │ 4. Federated │ │
│ │ Platform │ │ Governance │ │
│ │ │ │ │ │
│ │ Infrastructure │ │ Global standards, │ │
│ │ teams can use │ │ local autonomy │ │
│ │ independently │ │ │ │
│ └────────────────────┘ └────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘Principle 1: Domain Ownership
Teams that create/understand the data own and serve it.
Traditional (Centralized):
┌──────────┐ ┌──────────────────┐ ┌──────────┐
│ Sales │────────▶│ Central Data │────────▶│ All │
│ Team │ │ Team │ │ Consumers│
└──────────┘ │ │ └──────────┘
┌──────────┐ │ (Bottleneck) │
│ Marketing│────────▶│ │
└──────────┘ └──────────────────┘Data Mesh (Decentralized):
┌─────────────────┐ ┌──────────┐
│ Sales Domain │─────────────────────▶│ │
│ (owns sales │ │ Marketing│
│ data) │ │ Domain │
└─────────────────┘ │ │
│ └──────────┘
│ │
▼ ▼
┌─────────────────┐ ┌──────────┐
│ Marketing Domain│◀─────────────────────│ Sales │
│ (owns marketing │ │ Domain │
│ data) │ │ │
└─────────────────┘ └──────────┘Principle 2: Data as a Product
Each domain publishes data products with product management discipline.
| Characteristic | Description |
|---|---|
| Discoverable | Listed in data catalog with metadata |
| Addressable | Clear endpoint/path to access |
| Trustworthy | Quality SLAs, freshness guarantees |
| Self-describing | Schema, lineage, documentation |
| Interoperable | Standard formats, global IDs |
| Secure | Access controls, privacy compliance |
# Example: Data Product Contract
name: sales.orders
version: 2.0.0
owner: sales-data-team@company.com
description: All completed customer orders
schema:
- name: order_id
type: integer
description: Unique identifier
- name: customer_id
type: integer
description: FK to customers.customer_id
sla:
freshness: 1 hour
completeness: 99.9%
availability: 99.5%
access:
public: true
pii: falseData Contracts = “Shift Left” for Data
Just as software engineering shifted testing left (earlier in the pipeline), Data Contracts shift data quality left:
- Without Contracts: Upstream team changes schema → downstream pipelines break → data team discovers days later
- With Contracts: Schema change fails contract validation → caught in CI/CD before deployment
Data Contracts are the bridge between Microservices and the Data Platform. They prevent software engineers from accidentally breaking data pipelines with schema changes.
Principle 3: Self-Serve Platform
A data platform that enables domain teams to build/ship data products independently.
┌─────────────────────────────────────────────────────────────────┐
│ Self-Serve Data Platform │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Domain Teams Use │ │
│ ├──────────────────────────────────────────────────────┤ │
│ │ Data Product Templates │ CI/CD Pipelines │ │
│ │ Quality Frameworks │ Access Control │ │
│ │ Schema Registry │ Data Catalog │ │
│ └──────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Platform Team Provides │ │
│ ├──────────────────────────────────────────────────────┤ │
│ │ Compute (Spark/DBT) │ Storage (Lakehouse) │ │
│ │ Orchestration │ Observability │ │
│ │ Data Mesh Infra │ Security/Governance │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘Principle 4: Federated Computational Governance
Balance between global standards and local autonomy.
| Global (Federated) | Local (Domain) |
|---|---|
| Naming conventions | Schema design |
| Data quality minimums | Quality tests |
| PII handling rules | Business logic |
| Interoperability standards | Implementation |
| Audit requirements | Development pace |
Data Mesh Challenges
| Challenge | Mitigation |
|---|---|
| Coordination overhead | Strong platform team, clear contracts |
| Skill gaps | Training, embedded data engineers |
| Inconsistent quality | Automated quality gates |
| Discovery complexity | Robust data catalog |
| Governance complexity | Clear ownership, federated policies |
When to Use Data Mesh
| ✅ Good Fit | ❌ Poor Fit |
|---|---|
| Large organization (>100 engineers) | Small team (<20) |
| Multiple distinct domains | Single product/domain |
| Domain teams have data skills | No data skills in domains |
| Bottleneck at central data team | Central team working fine |
| Need for speed + scale | Simple analytics needs |
3. Combining Medallion + Data Mesh
The architectures complement each other:
┌─────────────────────────────────────────────────────────────────┐
│ Medallion + Data Mesh │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Sales Domain │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ Bronze │─▶│ Silver │─▶│ Gold │ ◀── Product │ │
│ │ └─────────┘ └─────────┘ └─────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ │ Published Data Product │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Marketing Domain │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ Bronze │─▶│ Silver │─▶│ Gold │ ◀── Product │ │
│ │ │(consumes│ └─────────┘ └─────────┘ │ │
│ │ │ Sales) │ │ │
│ │ └─────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘Implementation Pattern
- Each domain has its own Medallion layers (Bronze/Silver/Gold)
- Gold layer tables are the published Data Products
- Cross-domain consumption: Domain B’s Bronze can ingest Domain A’s Gold
- Platform provides shared tooling, catalog, governance
4. Tool Ecosystem
Platform Components
┌─────────────────────────────────────────────────────────────────┐
│ Modern Data Platform Stack │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ Ingestion │ │ Storage │ │ Transform │ │
│ ├───────────────┤ ├───────────────┤ ├───────────────┤ │
│ │ Fivetran │ │ Databricks │ │ dbt │ │
│ │ Airbyte │ │ Snowflake │ │ Spark │ │
│ │ Debezium │ │ Delta Lake │ │ SQLMesh │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ Orchestration │ │ Catalog │ │ Quality │ │
│ ├───────────────┤ ├───────────────┤ ├───────────────┤ │
│ │ Dagster │ │ DataHub │ │ Great Expect. │ │
│ │ Airflow │ │ Atlan │ │ Soda │ │
│ │ Prefect │ │ Unity Catalog │ │ Monte Carlo │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘Orchestration Deep Dive: Airflow vs Prefect
Two popular orchestration tools with different philosophies:
| Aspect | Apache Airflow | Prefect |
|---|---|---|
| Philosophy | DAGs as configuration | Python-first, decorators |
| Created | 2014 (Airbnb) | 2018 |
| Definition Style | Python + explicit DAG class | @flow / @task decorators |
| Dynamic DAGs | Requires workarounds | Native support |
| Local Development | Requires full setup | Simple python script.py |
| Managed Cloud | Astronomer, MWAA, GCP Composer | Prefect Cloud (free tier) |
| Ecosystem | Very mature, many plugins | Newer but growing fast |
| Learning Curve | Medium-high | Lower |
Code Comparison
Airflow:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def extract(): ...
def transform(): ...
with DAG('etl_pipeline', start_date=datetime(2024,1,1), schedule='@daily') as dag:
t1 = PythonOperator(task_id='extract', python_callable=extract)
t2 = PythonOperator(task_id='transform', python_callable=transform)
t1 >> t2Prefect:
from prefect import flow, task
@task
def extract(): ...
@task
def transform(data): ...
@flow(name="etl_pipeline")
def etl():
data = extract()
transform(data)
if __name__ == "__main__":
etl()When to Choose
| Choose Airflow | Choose Prefect |
|---|---|
| Enterprise with Airflow experience | New projects, rapid iteration |
| Need extensive connectors | Python-focused team |
| Using managed services (GCP/AWS) | Want simple local development |
| Long-term stable project | Dynamic workflows |
Data Mesh Specific Tools
| Category | Tools |
|---|---|
| Data Product Management | Datamesh Manager, DataOS |
| Data Contracts | Soda, datacontract CLI |
| Federated Catalog | DataHub, Atlan, Collibra |
| Self-Serve Platform | Databricks Unity Catalog, Starburst Galaxy |
5. Decision Framework
Architecture Selection
┌─────────────────────────────────────────────────────────────────┐
│ Architecture Decision │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Organization Size? │
│ │ │
│ ├── Small (<20 data people) │
│ │ └──▶ Medallion (centralized) │
│ │ │
│ ├── Medium (20-100) │
│ │ └──▶ Medallion + domain alignment │
│ │ │
│ └── Large (100+) │
│ │ │
│ ├── Domains have data skills? │
│ │ │ │
│ │ ├── Yes ──▶ Full Data Mesh │
│ │ └── No ──▶ Medallion + gradual shift │
│ │ │
│ └── Central team bottleneck? │
│ │ │
│ ├── Yes ──▶ Data Mesh │
│ └── No ──▶ Medallion (centralized) │
│ │
└─────────────────────────────────────────────────────────────────┘FinOps Warning: The Hidden Cost of Decentralization
Data Mesh and distributed Lakehouse architectures bring agility but can cause cost explosion:
| Risk | Cause | Mitigation |
|---|---|---|
| Duplicate compute | Multiple domains running similar queries | Shared intermediate tables, cross-domain marts |
| Unoptimized queries | Domain teams lack SQL optimization skills | Query analysis tools, training, guardrails |
| Storage sprawl | Every team creates copies “just in case” | Data lifecycle policies, automated cleanup |
| Uncapped serverless | Snowflake/BigQuery pay-per-query | Budget alerts, query cost limits |
Platform Team Responsibility: Provide Cost Observability dashboards showing:
- Per-domain compute/storage costs
- Cost trends and anomalies
- Query efficiency metrics
- Tools: Snowflake Cost Management, Databricks Cost Explorer, select star, Zenith
6. Summary: The City Analogy 🏙️
| Concept | City Analogy |
|---|---|
| Medallion | Highway system (Raw imports → Processing zones → Downtown business) |
| Bronze | Port/Airport (raw goods arrive as-is) |
| Silver | Warehouses (quality checked, sorted, standardized) |
| Gold | Retail stores (consumer-ready products) |
| Data Mesh | City districts (each district manages its own services, follows city codes) |
| Self-Serve Platform | City utilities (water, power everyone can connect to) |
| Federated Governance | City laws (global building codes, local zoning) |
Key Takeaways
- Medallion Architecture provides a clear layer pattern for data quality progression
- Data Mesh decentralizes ownership while maintaining interoperability
- They work together: Medallion as the pattern, Mesh as the organizational model
- Start simple: Begin with Medallion, evolve to Mesh as organization scales
- Platform is key: Self-serve infrastructure enables both patterns