Data Storage Evolution: From Warehouse to Lake to Lakehouse
Data Warehouse Data Lake Lakehouse Delta Lake Data Architecture
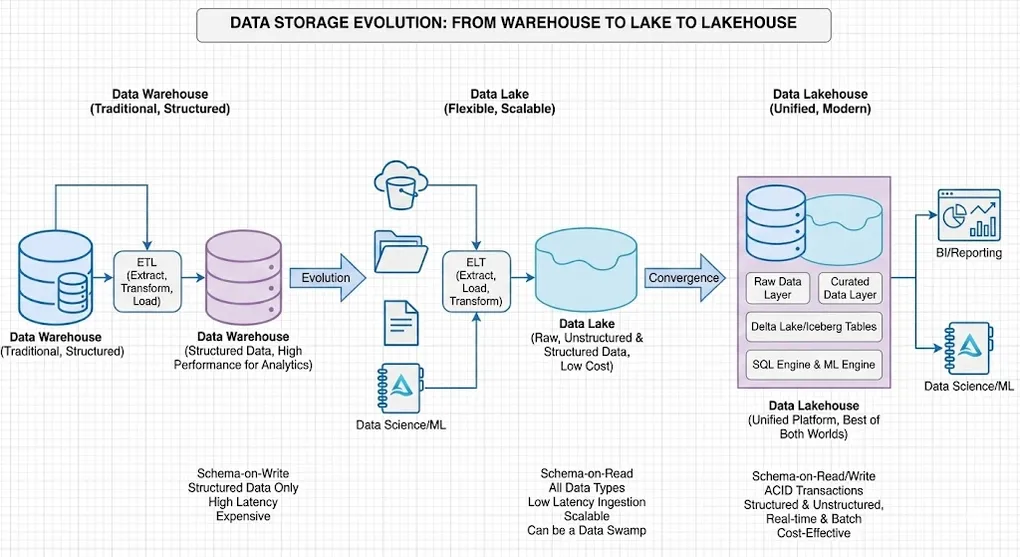
The Evolution Story
1990s 2010s 2020s │ │ │ ▼ ▼ ▼┌──────────┐ ┌──────────┐ ┌──────────────┐│ Data │ │ Data │ │ Data ││ Warehouse│───▶│ Lake │───▶│ Lakehouse │└──────────┘ └──────────┘ └──────────────┘ Structured Any Format Best of Both Schema-first Schema-later ACID + Scale
1. Data Warehouse
Definition
A Data Warehouse is a centralized repository optimized for analytical queries, storing structured, processed data in a predefined schema.
Without proper governance, Data Lakes become Data Swamps:
Issue
Description
No Schema
Can’t understand what data means
No Catalog
Can’t find what data exists
No Quality
Don’t know if data is reliable
No Lineage
Don’t know where data came from
Stale Data
Don’t know if data is current
Pros & Cons
✅ Pros
❌ Cons
Cheap storage
No ACID transactions
Any data format
Query performance issues
Massive scalability
Risk of becoming “data swamp”
Flexibility
Complex to manage
Good for ML/AI
No native BI support
Major Products
Type
Products
Storage
AWS S3, Azure Data Lake Storage, Google Cloud Storage
Processing
Apache Spark, Hadoop, Presto, Trino
Managed
AWS Lake Formation, Databricks, Azure Synapse
3. Data Lakehouse
Definition
A Data Lakehouse combines the best of Data Warehouses (ACID, governance, performance) with Data Lakes (scale, flexibility, low cost) using open table formats.
-- Query current stateSELECT * FROM orders;-- Query data as of 7 days agoSELECT * FROM orders TIMESTAMP AS OF '2024-01-01';-- Query specific versionSELECT * FROM orders VERSION AS OF 123;-- Restore to previous versionRESTORE TABLE orders TO VERSION AS OF 100;
Pros & Cons
✅ Pros
❌ Cons
ACID + cheap storage
Relatively new ecosystem
BI + ML unified
Learning curve
Schema flexibility
Vendor-specific features
Time travel
Metadata management overhead
Open formats
Not all tools support yet
Hidden Operational Costs: While storage is cheap, Lakehouse requires ongoing maintenance:
Compaction: Small files degrade query performance; need periodic compaction jobs
Vacuuming: Old snapshots accumulate; must clean up with VACUUM / OPTIMIZE
Self-hosted complexity: On AWS Glue/EMR, you manage all this yourself
Managed services (Databricks, Snowflake) handle this automatically, but at higher cost
Budget tip: Factor in operational overhead when comparing “cheap storage” costs.
Major Products
Type
Products
Table Formats
Delta Lake, Apache Iceberg, Apache Hudi
Platforms
Databricks, Snowflake, AWS, Azure, Dremio
The Blurring Lines (2025 Reality):
Modern cloud data warehouses have evolved to include Lakehouse capabilities:
Snowflake now supports Apache Iceberg external tables and bills itself as a “Data Cloud”
BigQuery supports federated queries on Delta Lake and has BigLake for unified access
Databricks SQL provides serverless, warehouse-grade BI query performance
This convergence means the “Warehouse vs. Lakehouse” distinction is increasingly philosophical rather than technical. Most modern platforms now offer a spectrum of capabilities.
4. Comparison Matrix
Feature Comparison
Feature
Warehouse
Lake
Lakehouse
Data Types
Structured only
Any
Any
Schema
Schema-on-Write
Schema-on-Read
Both
ACID
✅ Yes
❌ No
✅ Yes
Cost
$$$$
$
$$
Query Performance
⭐⭐⭐⭐⭐
⭐⭐
⭐⭐⭐⭐
Flexibility
⭐⭐
⭐⭐⭐⭐⭐
⭐⭐⭐⭐
ML/AI Support
⭐⭐
⭐⭐⭐⭐⭐
⭐⭐⭐⭐⭐
BI Support
⭐⭐⭐⭐⭐
⭐⭐
⭐⭐⭐⭐
Governance
⭐⭐⭐⭐⭐
⭐⭐
⭐⭐⭐⭐
Time Travel
Limited
❌ No
✅ Yes
Cost Structure
Component
Warehouse
Lake
Lakehouse
Storage
Expensive
Cheap
Cheap
Compute
Bundled (expensive)
Separate (flexible)
Separate (flexible)
Scaling
Vertical (costly)
Horizontal (easy)
Horizontal (easy)
5. Decision Framework
When to Use What
┌─────────────────────────────────────────────────────────────────┐│ Decision Tree │├─────────────────────────────────────────────────────────────────┤│ ││ Q1: Is all your data structured? ││ │ ││ ├── Yes ──▶ Q2: Is BI the primary use case? ││ │ │ ││ │ ├── Yes ──▶ DATA WAREHOUSE ││ │ │ ││ │ └── No ──▶ Q3: Need ACID + ML? ││ │ │ ││ │ ├── Yes ──▶ LAKEHOUSE ││ │ └── No ──▶ LAKE ││ │ ││ └── No ──▶ Q4: Need ACID transactions? ││ │ ││ ├── Yes ──▶ LAKEHOUSE ││ │ ││ └── No ──▶ DATA LAKE ││ │└─────────────────────────────────────────────────────────────────┘
By Organization Profile
Profile
Recommendation
Reason
Enterprise with existing DW
Hybrid (DW + Lakehouse)
Leverage existing investments
Startup, data-first
Lakehouse
Modern, flexible, cost-effective
ML/AI heavy workloads
Lake or Lakehouse
Raw data access, Python-friendly
Primarily BI/reporting
Warehouse or Lakehouse
Query performance matters
IoT/streaming data
Lake + Lakehouse
High volume, real-time needs
6. Summary: The Evolution Analogy 📚
Era
Storage
Analogy
Warehouse
Curated library
Books organized by Dewey Decimal, can only add properly cataloged books
Lake
Document storage
Everything dumped in boxes, find things yourself
Lakehouse
Smart library
All documents accepted, automatically organized, searchable, with history
Key Takeaway
The industry is converging on Lakehouse as the modern architecture, but the choice depends on your specific needs: