MongoDB Aggregation Pipeline: Data Processing & $lookup
Prerequisites: Understanding of MongoDB CRUD. See NOSQL 02 MongoDB Basics.
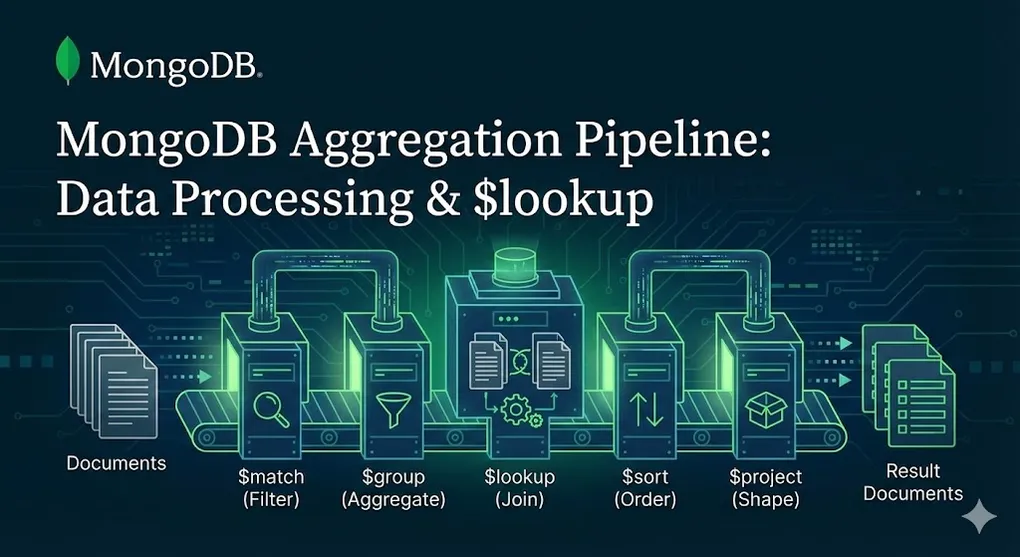
The Aggregation Framework is MongoDB’s answer to SQL’s GROUP BY, JOIN, and complex analytics queries. Think of it as a data processing factory.
Part A: Pipeline Concept
1. What is a Pipeline?
Data flows through a series of stages, each transforming the data:
graph LR
INPUT[Collection<br/>Documents] --> S1[$match<br/>Filter]
S1 --> S2[$group<br/>Aggregate]
S2 --> S3[$sort<br/>Order]
S3 --> S4[$project<br/>Shape]
S4 --> OUTPUT[Result<br/>Documents]
style INPUT fill:#3498db,color:#fff
style OUTPUT fill:#27ae60,color:#fffFactory Analogy:
| Stage | Factory Station | Action |
|---|---|---|
$match | Quality Control | Filter out defective items |
$group | Assembly Line | Combine parts into products |
$sort | Sorting Machine | Arrange by criteria |
$project | Packaging | Select what goes in the box |
2. Basic Syntax
db.collection.aggregate([
{ $stage1: { ... } },
{ $stage2: { ... } },
{ $stage3: { ... } }
]);Part B: Essential Stages
3. $match — Filter Documents (WHERE)
Filter documents early to reduce processing.
// SQL: SELECT * FROM orders WHERE status = 'completed'
db.orders.aggregate([
{ $match: { status: "completed" } }
]);
// Multiple conditions
db.orders.aggregate([
{ $match: {
status: "completed",
total: { $gte: 100 }
}}
]);Best Practice: Always put $match first when possible — it can use indexes!
4. $project — Select Fields (SELECT)
Choose which fields to include/exclude or create new ones.
// SQL: SELECT name, email, total FROM orders
db.orders.aggregate([
{ $project: {
name: 1,
email: 1,
total: 1,
_id: 0 // Exclude _id
}}
]);
// Create computed field
db.orders.aggregate([
{ $project: {
name: 1,
totalWithTax: { $multiply: ["$total", 1.1] } // Add 10% tax
}}
]);[!TIP] project: If you only want to add a field without manually listing all existing fields, use
$addFieldsinstead of$project. It preserves all original fields automatically:// $project requires listing all fields you want to keep { $project: { name: 1, email: 1, total: 1, discount: { $multiply: ["$total", 0.1] } } } // $addFields just adds/modifies, keeps everything else { $addFields: { discount: { $multiply: ["$total", 0.1] } } }
5. $group — Aggregate Data (GROUP BY)
Group documents and compute aggregates.
// SQL: SELECT category, SUM(amount) as total
// FROM sales GROUP BY category
db.sales.aggregate([
{ $group: {
_id: "$category", // Group by category
totalSales: { $sum: "$amount" },
avgSales: { $avg: "$amount" },
count: { $sum: 1 }
}}
]);Common Accumulators
| Accumulator | SQL Equivalent | Example |
|---|---|---|
$sum | SUM() | { $sum: "$amount" } |
$avg | AVG() | { $avg: "$price" } |
$min | MIN() | { $min: "$date" } |
$max | MAX() | { $max: "$score" } |
$first | (subquery) | { $first: "$name" } |
$last | (subquery) | { $last: "$timestamp" } |
$push | (no equivalent) | { $push: "$item" } |
$addToSet | (no equivalent) | { $addToSet: "$tag" } |
Group by Multiple Fields
// SQL: GROUP BY year, month
db.sales.aggregate([
{ $group: {
_id: {
year: { $year: "$date" },
month: { $month: "$date" }
},
monthlySales: { $sum: "$amount" }
}}
]);6. $sort — Order Results (ORDER BY)
// SQL: ORDER BY total DESC
db.orders.aggregate([
{ $sort: { total: -1 } } // -1 = descending, 1 = ascending
]);
// Sort by multiple fields
db.orders.aggregate([
{ $sort: { status: 1, total: -1 } }
]);7. skip — Pagination
// SQL: LIMIT 10 OFFSET 20
db.orders.aggregate([
{ $sort: { date: -1 } },
{ $skip: 20 },
{ $limit: 10 }
]);Part C: $lookup — The JOIN
8. $lookup Basics (LEFT JOIN)
Connect documents from different collections.
// SQL: SELECT * FROM orders LEFT JOIN customers ON orders.customerId = customers._id
db.orders.aggregate([
{ $lookup: {
from: "customers", // Join with this collection
localField: "customerId", // Field in orders
foreignField: "_id", // Field in customers
as: "customerDetails" // Output array name
}}
]);Output:
{
"_id": ObjectId("order123"),
"total": 500,
"customerId": ObjectId("cust456"),
"customerDetails": [ // Array with matched documents
{
"_id": ObjectId("cust456"),
"name": "Alice",
"email": "alice@example.com"
}
]
}9. unwind
Since $lookup returns an array, use $unwind to flatten it:
db.orders.aggregate([
{ $lookup: {
from: "customers",
localField: "customerId",
foreignField: "_id",
as: "customer"
}},
{ $unwind: "$customer" }, // Flatten the array
{ $project: {
orderId: "$_id",
total: 1,
customerName: "$customer.name", // Now accessible as object
customerEmail: "$customer.email"
}}
]);10. Advanced $lookup (Pipeline)
For complex joins with conditions:
db.orders.aggregate([
{ $lookup: {
from: "products",
let: { orderItems: "$items" }, // Pass variables
pipeline: [
{ $match: {
$expr: { $in: ["$_id", "$$orderItems.productId"] }
}},
{ $project: { name: 1, price: 1 } }
],
as: "productDetails"
}}
]);Part D: Real-World Examples
11. Sales Report by Category
Task: Get total sales and average order value per category for 2024.
db.orders.aggregate([
// Stage 1: Filter 2024 orders
{ $match: {
orderDate: {
$gte: ISODate("2024-01-01"),
$lt: ISODate("2025-01-01")
}
}},
// Stage 2: Unwind items array
{ $unwind: "$items" },
// Stage 3: Group by category
{ $group: {
_id: "$items.category",
totalRevenue: { $sum: { $multiply: ["$items.price", "$items.qty"] } },
totalOrders: { $sum: 1 },
avgOrderValue: { $avg: { $multiply: ["$items.price", "$items.qty"] } }
}},
// Stage 4: Sort by revenue
{ $sort: { totalRevenue: -1 } },
// Stage 5: Format output
{ $project: {
category: "$_id",
totalRevenue: { $round: ["$totalRevenue", 2] },
totalOrders: 1,
avgOrderValue: { $round: ["$avgOrderValue", 2] },
_id: 0
}}
]);SQL Equivalent:
SELECT
category,
SUM(price * qty) as totalRevenue,
COUNT(*) as totalOrders,
AVG(price * qty) as avgOrderValue
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
WHERE order_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY category
ORDER BY totalRevenue DESC;12. Customer Order Summary with $lookup
Task: Get each customer’s total spending and order count.
db.customers.aggregate([
// Join with orders
{ $lookup: {
from: "orders",
localField: "_id",
foreignField: "customerId",
as: "orders"
}},
// Calculate metrics
{ $project: {
name: 1,
email: 1,
orderCount: { $size: "$orders" },
totalSpent: { $sum: "$orders.total" },
avgOrderValue: { $avg: "$orders.total" }
}},
// Filter active customers
{ $match: { orderCount: { $gt: 0 } } },
// Sort by spending
{ $sort: { totalSpent: -1 } },
// Top 10
{ $limit: 10 }
]);13. Time-Series Aggregation
Task: Daily order count for the past week.
db.orders.aggregate([
{ $match: {
orderDate: { $gte: new Date(Date.now() - 7*24*60*60*1000) }
}},
{ $group: {
_id: {
year: { $year: "$orderDate" },
month: { $month: "$orderDate" },
day: { $dayOfMonth: "$orderDate" }
},
orderCount: { $sum: 1 },
revenue: { $sum: "$total" }
}},
{ $sort: { "_id.year": 1, "_id.month": 1, "_id.day": 1 } },
{ $project: {
date: {
$dateFromParts: {
year: "$_id.year",
month: "$_id.month",
day: "$_id.day"
}
},
orderCount: 1,
revenue: 1,
_id: 0
}}
]);Part E: Performance Tips
14. Pipeline Optimization
graph TD
subgraph "❌ Slow Pipeline"
A1[$project] --> A2[$sort]
A2 --> A3[$match]
end
subgraph "✅ Fast Pipeline"
B1[$match] --> B2[$sort]
B2 --> B3[$project]
end
style A3 fill:#e74c3c,color:#fff
style B1 fill:#27ae60,color:#fffOptimization Rules
| Rule | Reason |
|---|---|
Put $match first | Uses indexes, reduces documents |
Put $project last | Keeps data for processing |
Limit $lookup results | Avoid loading huge arrays |
Use allowDiskUse: true | For large datasets |
[!WARNING] Index Usage Limitation: MongoDB can only use indexes on the first stage of the pipeline (specifically
$matchand$sort). Once data passes through$group,$project, or$unwind, subsequent stages cannot use the original collection’s indexes — the data is already transformed in memory.
// Allow disk use for large aggregations
db.orders.aggregate([
{ $group: { _id: "$category", total: { $sum: "$amount" } } }
], { allowDiskUse: true });15. Stage-to-SQL Mapping Reference
| MongoDB Stage | SQL Clause |
|---|---|
$match | WHERE / HAVING |
$project | SELECT |
$group | GROUP BY |
$sort | ORDER BY |
$limit | LIMIT |
$skip | OFFSET |
$lookup | LEFT JOIN |
$unwind | (unnest array) |
$count | COUNT(*) |
$out | SELECT INTO |
Summary
Pipeline Stage Cheat Sheet
| Stage | Purpose | Example |
|---|---|---|
$match | Filter | { status: "active" } |
$project | Shape | { name: 1, total: 1 } |
$group | Aggregate | { _id: "$category", sum: { $sum: "$price" } } |
$sort | Order | { date: -1 } |
$limit | Cap results | 10 |
$lookup | Join | { from: "users", ... } |
$unwind | Flatten array | "$items" |
Key Takeaways
- Pipeline = Factory Line — data flows through stages
- $match first — filter early for performance
- $lookup = LEFT JOIN — connect collections
- $unwind — flatten arrays for processing
- Use indexes — sort can use indexes
💡 Practice Questions
Conceptual
-
What is the MongoDB aggregation pipeline? How is it different from
find()? -
Explain the ESR principle in ordering pipeline stages. Why does putting
$matchfirst improve performance? -
What does
$lookupdo and how is it similar to SQLJOIN? -
When would you use
$unwindand what does it do?
Hands-on
// Write an aggregation pipeline to:
// 1. Filter orders from 2024
// 2. Group by customer email
// 3. Calculate total spent and order count per customer
// 4. Sort by total spent descending
// 5. Return top 5 customers💡 View Answer
db.orders.aggregate([
{ $match: { orderDate: { $gte: ISODate("2024-01-01"), $lt: ISODate("2025-01-01") } } },
{ $group: { _id: "$customerEmail", totalSpent: { $sum: "$total" }, orderCount: { $sum: 1 } } },
{ $sort: { totalSpent: -1 } },
{ $limit: 5 },
{ $project: { email: "$_id", totalSpent: 1, orderCount: 1, _id: 0 } }
]);Scenario
- Performance: An aggregation pipeline is slow. The first stage is
$project, then$match. What’s wrong and how would you fix it?
💡 View Answer
Problem: $project as the first stage forces MongoDB to:
- Full collection scan — cannot use indexes
- Transform every document — creates new document structure in memory
- Lose index access — the following
$matchoperates on transformed data, so it cannot use any collection indexes
Fix: Swap the order — put $match first:
// ❌ Slow: $project first
db.orders.aggregate([
{ $project: { status: 1, total: 1 } },
{ $match: { status: "completed" } } // Cannot use index!
]);
// ✅ Fast: $match first
db.orders.aggregate([
{ $match: { status: "completed" } }, // Uses index on status
{ $project: { status: 1, total: 1 } }
]);Rule of Thumb: Always filter ($match) before transforming ($project/$group).