MongoDB Schema Design: Embedding vs Referencing
Prerequisites: Understanding of MongoDB basics. See NOSQL 02 MongoDB Basics.
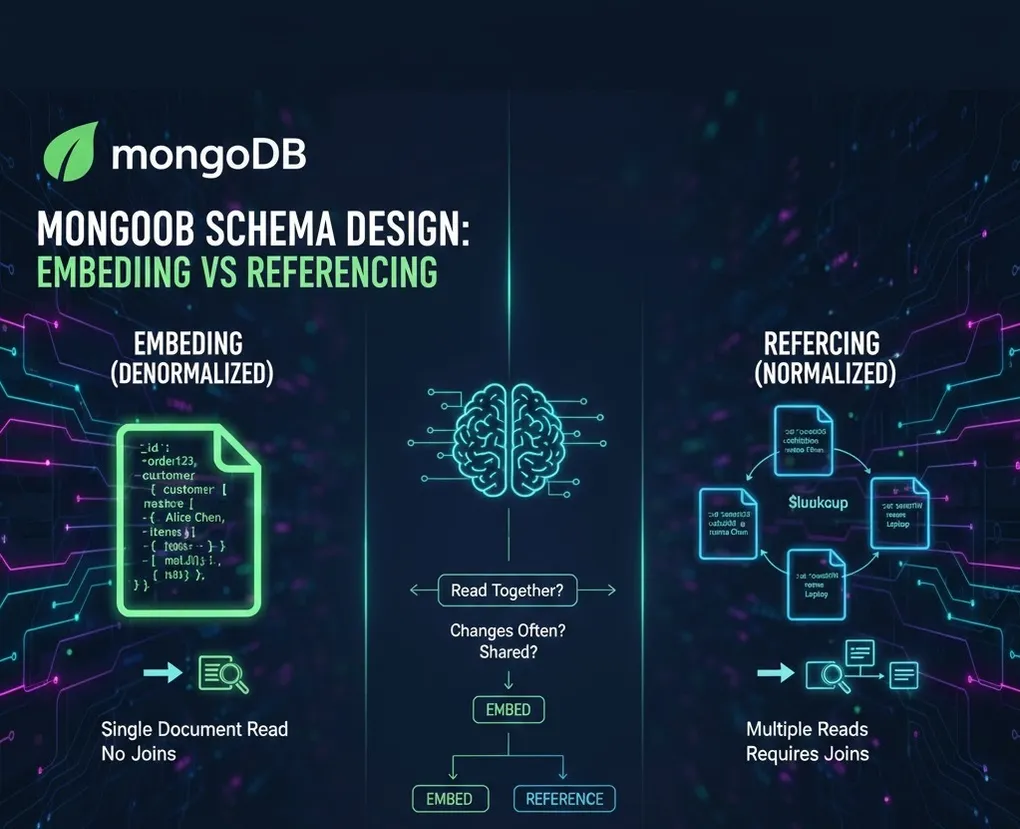
The biggest mindset shift from SQL to MongoDB is how you structure your data. Forget normalization — embrace denormalization (when appropriate).
Part A: The Two Approaches
1. Embedding vs Referencing
graph TD
subgraph "Embedding (Denormalized)"
E1["Order Document"]
E2["{ customer: {...}, items: [...] }"]
E1 --> E2
end
subgraph "Referencing (Normalized)"
R1["Order Document"]
R2["{ customerId: ObjectId }"]
R3["Customer Document"]
R1 --> R2
R2 -.->|lookup| R3
end
style E2 fill:#27ae60,color:#fff
style R2 fill:#3498db,color:#fff| Approach | When to Use | Trade-off |
|---|---|---|
| Embedding | Data read together | Duplication, larger docs |
| Referencing | Data updates independently | Requires $lookup (join) |
2. Embedding (Denormalization)
Put related data inside the parent document.
// Order with embedded customer and items
{
"_id": ObjectId("order123"),
"orderDate": ISODate("2024-03-15"),
"status": "shipped",
"customer": { // Embedded!
"name": "Alice Chen",
"email": "alice@example.com",
"address": "123 Main St, Taipei"
},
"items": [ // Embedded array!
{ "product": "Laptop", "price": 1200, "qty": 1 },
{ "product": "Mouse", "price": 25, "qty": 2 }
],
"total": 1250
}Advantages
| Benefit | Explanation |
|---|---|
| Single read | Get everything in one query |
| Atomic writes | Update order + items in one operation |
| No joins | No $lookup needed |
Disadvantages
| Drawback | Explanation |
|---|---|
| Data duplication | Customer info copied to every order |
| Update anomalies | If Alice changes email, update ALL her orders |
| Document size limit | 16 MB max per document |
[!WARNING] Write Contention: Even for 1:Few relationships, embedding can cause problems if the document is frequently updated by many concurrent writers. Example: A viral post’s
likesarray with thousands of likes per second causes write contention on that single document. In high-concurrency scenarios, consider referencing or using counters in a separate document.
3. Referencing (Normalization)
Store related data in separate collections with ID references.
// Order document (references customer)
{
"_id": ObjectId("order123"),
"orderDate": ISODate("2024-03-15"),
"customerId": ObjectId("customer456"), // Reference!
"items": [
{ "productId": ObjectId("prod789"), "qty": 1 },
{ "productId": ObjectId("prod012"), "qty": 2 }
]
}
// Customer document (separate collection)
{
"_id": ObjectId("customer456"),
"name": "Alice Chen",
"email": "alice@example.com"
}
// Product document (separate collection)
{
"_id": ObjectId("prod789"),
"name": "Laptop",
"price": 1200
}Advantages
| Benefit | Explanation |
|---|---|
| No duplication | Customer data in one place |
| Easy updates | Change email once, everywhere sees it |
| Smaller documents | References are just ObjectIds |
Disadvantages
| Drawback | Explanation |
|---|---|
| Multiple queries | Need $lookup to join data |
| Not atomic | Can’t update across collections atomically |
| Application complexity | More queries to manage |
[!WARNING] Sharding Limitation: In distributed (sharded) clusters,
$lookupacross different shards has significant performance overhead. Earlier MongoDB versions had restrictions on cross-shard$lookup. If you plan to scale horizontally, prefer embedding to keep related data on the same shard.
Part B: Decision Framework
4. The Embedding vs Reference Decision Tree
flowchart TD
START[Data Relationship] --> Q1{How often read<br/>together?}
Q1 -->|Always| EMBED[Embed]
Q1 -->|Sometimes| Q2{Child data<br/>changes often?}
Q2 -->|Rarely| EMBED
Q2 -->|Frequently| REF[Reference]
Q1 -->|Rarely| REF
REF --> Q3{Is child shared<br/>by many parents?}
Q3 -->|Yes| REF_FINAL[Reference]
Q3 -->|No| Q4{Child has<br/>own lifecycle?}
Q4 -->|Yes| REF_FINAL
Q4 -->|No| EMBED
style EMBED fill:#27ae60,color:#fff
style REF_FINAL fill:#3498db,color:#fff5. Quick Reference Table
| Scenario | Recommendation | Reason |
|---|---|---|
| User + Addresses | Embed | Addresses belong to user |
| Order + Items | Embed | Items only exist in that order |
| Blog + Comments | Embed (if few) | Comments read with blog |
| Blog + Comments | Reference (if many) | Avoid huge documents |
| Product + Category | Reference | Category shared by many products |
| User + Orders | Reference | Orders have own lifecycle |
Part C: Real-World Patterns
6. One-to-One: Embed
Example: User profile + settings
// ✅ Good: Embed
{
"_id": ObjectId("user123"),
"username": "alice",
"email": "alice@example.com",
"settings": { // 1:1 relationship
"theme": "dark",
"language": "en",
"notifications": true
}
}7. One-to-Few: Embed
Example: User + addresses (typical person has 1-3 addresses)
// ✅ Good: Embed
{
"_id": ObjectId("user123"),
"name": "Alice",
"addresses": [
{ "type": "home", "city": "Taipei" },
{ "type": "work", "city": "Hsinchu" }
]
}8. One-to-Many: It Depends
Small number of children → Embed
// Blog with 10-20 comments: Embed
{
"_id": ObjectId("blog123"),
"title": "MongoDB Guide",
"comments": [
{ "user": "Bob", "text": "Great post!", "date": ISODate(...) },
// ... up to ~20 comments
]
}Large number of children → Reference
// Blog with 1000+ comments: Reference
// Blog document
{ "_id": ObjectId("blog123"), "title": "MongoDB Guide" }
// Comments collection
{ "_id": ObjectId("c1"), "blogId": ObjectId("blog123"), "text": "Great!" }
{ "_id": ObjectId("c2"), "blogId": ObjectId("blog123"), "text": "Thanks!" }
// ... thousands of comments9. Many-to-Many: Reference with Array
Example: Students and Courses
// Student document
{
"_id": ObjectId("student1"),
"name": "Alice",
"courseIds": [
ObjectId("course1"),
ObjectId("course2")
]
}
// Course document
{
"_id": ObjectId("course1"),
"name": "Database 101",
"studentIds": [
ObjectId("student1"),
ObjectId("student2")
]
}Part D: E-Commerce Case Study
10. SQL Design (Normalized)
erDiagram
Customers ||--o{ Orders : places
Orders ||--o{ OrderItems : contains
OrderItems }o--|| Products : references
Products }o--|| Categories : belongs_to
Customers {
int id PK
string name
string email
}
Orders {
int id PK
int customer_id FK
datetime order_date
}
OrderItems {
int id PK
int order_id FK
int product_id FK
int quantity
}
Products {
int id PK
string name
decimal price
int category_id FK
}Problem: Displaying one order requires 4 table JOINs.
11. MongoDB Design (Denormalized)
graph LR
subgraph "SQL: 4 Tables + JOINs"
direction TB
C[Customers] -.-> O[Orders]
O -.-> OI[OrderItems]
OI -.-> P[Products]
end
subgraph "MongoDB: 1 Document"
direction TB
DOC["{<br/> customer: {...},<br/> items: [{...}],<br/> total: 2624<br/>}"]
end
style C fill:#e74c3c,color:#fff
style O fill:#e74c3c,color:#fff
style OI fill:#e74c3c,color:#fff
style P fill:#e74c3c,color:#fff
style DOC fill:#27ae60,color:#fff// Orders collection - Hybrid approach
{
"_id": ObjectId("order123"),
"orderDate": ISODate("2024-03-15"),
"status": "delivered",
// Embedded: Snapshot of customer at order time
"customer": {
"_id": ObjectId("cust456"), // Keep reference for updates
"name": "Alice Chen",
"shippingAddress": "123 Main St"
},
// Embedded: Order items with product snapshot
"items": [
{
"productId": ObjectId("prod789"), // Reference for lookup
"name": "MacBook Pro", // Snapshot (won't change)
"priceAtPurchase": 2499, // Historical record
"quantity": 1
}
],
"subtotal": 2499,
"tax": 125,
"total": 2624
}Why This Works
| Field | Strategy | Reason |
|---|---|---|
customer._id | Reference | Can lookup current customer |
customer.name | Snapshot | Display without $lookup |
items[].productId | Reference | Can link to product page |
items[].priceAtPurchase | Snapshot | Historical record (price may change) |
Part E: Anti-Patterns to Avoid
12. Massive Arrays (Unbounded Growth)
// ❌ Bad: Array grows forever
{
"blogId": ObjectId("..."),
"comments": [
// ... 50,000 comments -> Document too large!
]
}
// ✅ Good: Separate collection with pagination
db.comments.find({ blogId: ObjectId("...") })
.sort({ date: -1 })
.limit(20);13. Deep Nesting
// ❌ Bad: Too deep (hard to query/update)
{
"level1": {
"level2": {
"level3": {
"level4": {
"data": "buried treasure"
}
}
}
}
}
// ✅ Good: Keep nesting to 2-3 levels max
{
"settings": {
"notifications": {
"email": true,
"sms": false
}
}
}14. Storing Lookup Tables as Embedded
// ❌ Bad: Category duplicated in every product
{ "name": "Laptop", "category": { "id": 1, "name": "Electronics" } }
{ "name": "Phone", "category": { "id": 1, "name": "Electronics" } }
// If category name changes -> update ALL products!
// ✅ Good: Reference for shared data
{ "name": "Laptop", "categoryId": ObjectId("cat1") }
{ "name": "Phone", "categoryId": ObjectId("cat1") }
// + Categories collection with single source of truthSummary
Embedding vs Referencing
| Embed | Reference | |
|---|---|---|
| Read performance | Fast (single query) | Slower ($lookup needed) |
| Write complexity | Simple (atomic) | Complex (multiple collections) |
| Data consistency | May have duplicates | Single source of truth |
| Document size | Can grow large | Stays small |
Quick Decision Guide
| Relationship | Size | Update Frequency | Recommendation |
|---|---|---|---|
| 1:1 | Any | Any | Embed |
| 1:Few | < 20 | Low | Embed |
| 1:Many | < 100 | Low | Embed |
| 1:Many | 100+ | Any | Reference |
| Many:Many | Any | Any | Reference (arrays) |
Golden Rules
- Embed what you read together
- Reference what changes independently
- Denormalize for read performance
- Keep documents under 16 MB
- Avoid unbounded array growth
💡 Practice Questions
Conceptual
-
When should you embed data vs reference data in MongoDB?
-
What is the 16 MB document size limit and why is it a concern for embedded arrays?
-
Explain the concept of a “snapshot” in schema design. When would you store a snapshot instead of a reference?
Hands-on
// Design a schema for a blog application with:
// - Posts (title, content, author, createdAt)
// - Comments (user, text, createdAt) - assume ~50 comments per post average
// Should comments be embedded or referenced? Show your document structure.💡 View Answer
For ~50 comments per post, embedding is reasonable:
// Posts collection
{
"_id": ObjectId("post123"),
"title": "MongoDB Schema Design",
"content": "...",
"author": {
"_id": ObjectId("user789"),
"name": "Alice" // Snapshot for display
},
"createdAt": ISODate("2024-03-15"),
"comments": [
{ "user": "Bob", "text": "Great post!", "createdAt": ISODate(...) },
// ... up to ~50-100 comments
]
}If comments grow to 1000+, move to separate collection:
// Comments collection
{ "_id": ObjectId(...), "postId": ObjectId("post123"), "user": "Bob", "text": "..." }Scenario
- Anti-pattern: A developer embedded an array of “followers” inside each user document. A popular user has 1 million followers. What problems will occur?
💡 View Answer
Problems:
-
16 MB Hard Limit: 1 million
ObjectIdvalues = ~12 MB (each ObjectId is 12 bytes). Add other fields and you easily exceed the 16 MB limit, causingBSONObj size is invaliderror — the document cannot be saved. -
Write Contention: Every new follower requires updating the same document, causing lock contention under high concurrency.
-
Slow Operations: Loading/updating a 12+ MB array is extremely slow.
Solution: Use a separate collection for follower relationships:
// Followers collection (Reference pattern)
{ "_id": ObjectId(...), "userId": ObjectId("popular_user"), "followerId": ObjectId("fan123") }Store only a follower count in the user document, use $inc for atomic updates.